
“ 语音交互设计仅靠书本上的知识是不够的,在实际项目中,除了要了解需求、目标用户以外,还要了解语音设计所应用的场景、技术水平、设备配置等,从而有的放矢的展开设计。本文结合参与的项目,将语音交互设计的流程、设计关键点以及如何通过设计化解技术限制,和大家进行分享。”
相关文章:《语音交互设计(一):VUI发展及特征》
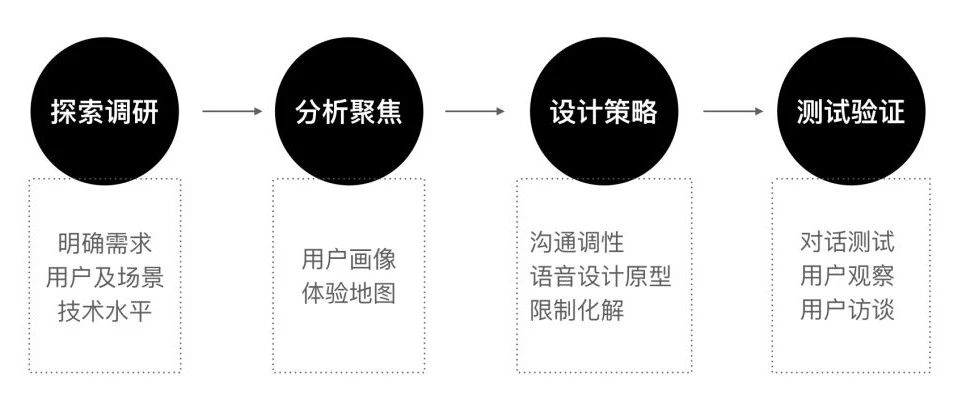
图1 · 语音交互设计流程
1. 探索调研
1.1 明确需求
笔者所参与的项目是“公司机房服务的工业机器人” 的语音设计,这类产品的功能比家用设备的更为强大,除了语音外,它支持:行走、人脸识别、任务解析、数据采集等,同时场景也更为复杂。首先机房环境声音嘈杂、环境复杂;它的性质又决定对人员的安全要求极高,需要准确的识别与判断,这些在了解需求阶段是必须明确的环节。
机器人的主要功能就是辅助参观人员、维修人员、驻场工程师更好的完成机房工作,实现机房业务管理智能化,提高运维管理效率和准确率。那么作为体验设计方,则是通过各场景、各环节的体验设计,让人与机器人、与系统的交互高效、自然、流畅,让智能化的机房日常运维管理更加完善。
1.2 了解业务场景及目标用户
在上一篇文章中对主要的五种场景(智能家居、车载驾驶、企业应用、医疗、教育)分别进行了介绍。不同的场景,意味着用户不同的需求和目的,对语音交互的要求也不相同。下面就针对机房环境进行场景分析与设计难点的介绍。

图2 · 机器人功能及场景特征
1.2.1 工作场景
恒定噪音:作为机房服务场景的语音机器人,使用环境声音的嘈杂首先会影响语音录入的准确性。语音交互包含三个重要部分:自然语音识别、自然语音理解、自然语音生成, 因此解决设备“听”清楚的问题,关系到后续流程能否顺利展开。这里就需要依靠“设备技术”来解决,通过优化听筒的降噪能力,尽量过滤掉噪音。
环境复杂:机房中机柜众多,服务器高低不一、设备管线错综复杂,如图3:这给机器人的正常作业带来挑战,尤其是这种对安全性和准确性要求很高的场景。首先,机房包间中的环境光线影响机器人对人脸的识别和机柜数据的读取;其次,机柜中服务器位置高低不同,机器人需要不断调整摄像头的角度,以确保采集到完整信息,也可能存在视野死角导致无法全部读取。这一部分,则需要通过不断的测试与调整,提高机器人自身性能,使其更好的适应现场环境,具有设备、网络线缆的识别能力,减少不必要的“人为”破坏,增加人脸、数据识别的准确性。
 图3 · 一般的机房环境
图3 · 一般的机房环境
空间局促:在机房中机柜之间的空间不大,过道也比较狭窄,这给机器人行走带来一定影响。第一:行走速度不能过快,由于机器人自重150斤,走路太快会有惯性,有可能出现不小心撞到机柜的情况;第二:很多时候无法和人并行走路,这导致人机互动体验不好,再加上机器人本身走的慢,很有可能出现“人走在前面,遮挡住机器人视线”的问题。为此,在设计语音时,只要机器人感应到有遮挡,便会播报:“我好像被挡住了,请保持前方通畅”,以此来友善的提醒用户,减少这种封闭环境下用户的不适应。
1.2.2 目标用户
通过团队的调研,收集到在整个数据中心有5类用户,其中会进入机房与机器人直接发生交互的主要有三类:访客、厂商、数据中心驻场,如图4。图中是这三类用户的工作内容与场景接触点,确认目标用户,便于设计对后续用户调研的聚焦与体验地图的梳理。
 图4 · 用户分析
图4 · 用户分析
1.3 技术水平
1.3.1 硬件
硬件来说,目前的语音产品包括:纯语音(天猫精灵)和语音及界面结合(iphone的siri)两种配置。在设计之初,我们需要了解语音产品的基本硬件配置,这其中也包括麦克风、摄像头、听筒、设备联网程度等,因为,产品的配置会影响我们后期的设计策略与体验。例如问语音产品:“世界十大旅游胜地都是哪些?、中国56个名族都有什么?”,即便语音助手可以准确的告诉我们答案,但无疑是一个沉重的认知与记忆负担,如果配合屏幕来显示,情况会好很多。最好的人机交互形式是混合型的,即GUI+VUI(图像交互+语音交互)如图echo show,如果你所设计的是纯语音产品,那么在设计时则需要考虑更多的引导、容错、提示等。

图5 · 亚马逊Echo Show
本次项目中所涉及的机器人不带显示屏幕,并且语音不联网,这就意味着所有对话都需要提前预设好,设计师需要根据可能出现的情况,将对话内容完善,并且做必要引导,让用户按照系统期望的流程进行,确保工作顺利、安全的开展。如下图:在设计时,对于较长对话,在内容中加入“如果没听清楚,请回复我‘重复一遍’〞的提示,避免用户没有听清而错过信息;同时对于用户的回答,也给予答案提示,“维修结束时请回复我‘维修结束’ 〞通过设计去尽量规避机器人硬件的缺陷,减少“答非所问”的错误发生率和用户回答的发散,提高语音交互流程的顺畅。

图6 · 语音交互引导示例
1.3.2 算法:
算法方面,则需要通过机器“深度学习”,不断完善语音识别、语音理解及语音合成的水平。目前,语音识别方面还面临很多技术挑战,如:
- (1) 噪音
恒定噪音(公路上、机房中) 和突发噪音(突然异常大声)。
- (2)多人讲话:
多人讲话,设备能否识别其中一条信息;同样多设备时,如何辨别自己的主人在说话。
- (3)儿童:
儿童说话逻辑性较弱,容易出现口吃、长时间停顿等现象。
- (4)短句:
“是”、“不”这种短句提供的数据信息较少,会造成识别率低。
- (5)多音字:
比如人名,同样的音会有多种书写文字“清”“轻”,会影响语音识别的准确性。
更多关于机器人“深度学习”的内容大家可以自行了解,这里不展开讨论。
2. 分析聚焦
具体在分析聚焦阶段,设计的思路是:用户调研 > 聚类分析 > 角色建模 > 体验设计。围绕与机器人相关的机房工作人员,提升他们在工作中的服务体验,确保顺畅、安全、高效的工作流程。
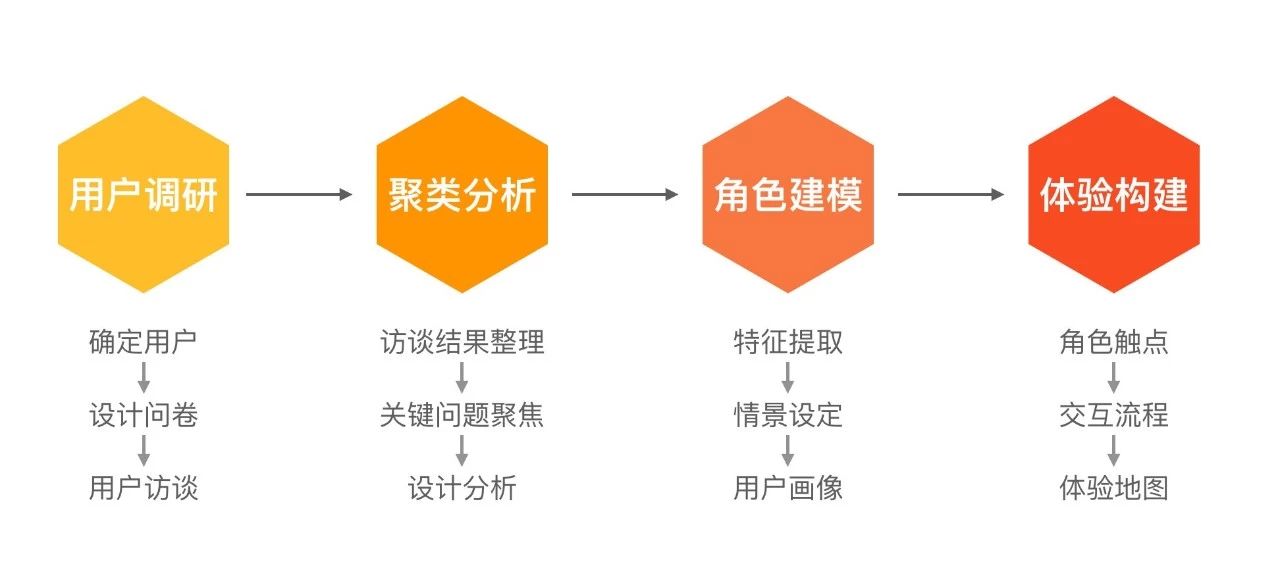
图7 · 用户分析
2.1用户画像
针对第一章节中定位的三类用户,我们通过问卷,进⾏用户访谈,旨在了解各个不同角⾊的用户他们工作的内容、需求,以及有哪些痛点可以抽取出来由机器人替代,从而优化各角色的服务体验。

图8 · 用户问卷设计
共计访问10位用户,包含各个角色。访问之后,我们对用户访谈的结果进行整理,整理维度有:日常工作描述、工作中的需求与期望、对机器人工作融入的畅想与担心。在此基础上,完成用户角色建模,通过各类角色的工作内容、痛点、情景设定、工作评分这四个主要方向进行描述与呈现,以驻场工程师为例,具体的用户角色卡如下图所示:

图9 · 用户角色信息卡–驻场
最终根据用户画像和调研中收集的问题进行聚类分析,集中梳理与归类,得到用户诉求,即对机器人应用场景下的机房服务的“服务主张”,围绕“安全”“规范”“高效”三个方面。这三个机房服务的体验目标,也是作为后续机器人语音设计所要达到的基本要求。

图10 · 机房服务主张
2.2 体验地图
与机器人交互的环节涉及到线上、线下,从线上任务的提交到线下与机器人真实交互,再到过程中机器人收集信息的回传,整个闭环链路构成机房机器人服务体验的核心。以其中导览场景为例,介绍整体流程,线上的主要触点:任务申请 > 任务生成 > 任务确认 > 任务存档;线下的主要触点:任务下发 > 机器人唤醒及用户身份验证 > 任务执行 > 任务结束,具体的触点详情及语音流程见下图:
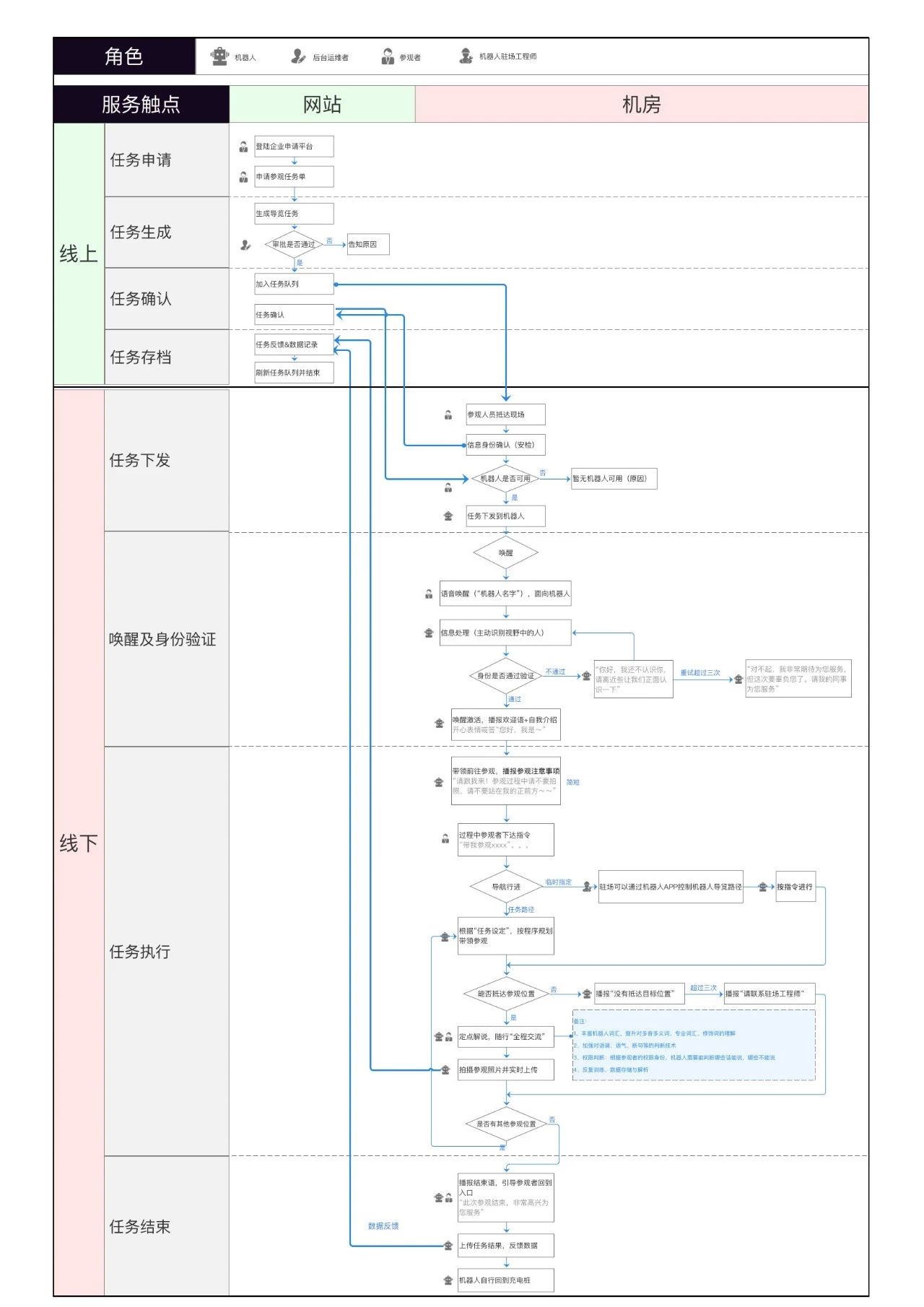
图11 · 机器人服务体验流程
经过体验地图的梳理与流程规划,去构建合理、有序的流程,在任务执行过程中保证人机交互“自然、亲切、可靠”的体验,同时配合技术优化,完善机器人语音交互的丰富度,在语音交互设计中也会利用适当的引导与必要的提示,以更自然的方式消除异常时的尴尬,快速做到工作衔接。
3. 设计策略
3.1 定义角色人格
VUI产品是一个虚拟的人与用户直接沟通,因此,沟通对象的语气风格、性格等则是用户接触的第一感受,为了提升真实性,定义一个符合自己产品调性的角色至关重要,也是着手真正语音设计的第一步。
这里的角色,是通过应用程序的语音及语言选择,塑造一个符合品牌服务特征,并且具有人格或心理的形象【1】。角色人格包含:
- 公司所传达的态度
- 产品的个性特征
- 期望别人如何看待它
在本次项目中,笔者在开始设计时,也先对机器人的语音调性和语气风格做了定义,根据语音交互场景和机器人的功能特性,语气规范追求的是:笃定、尊重、正式、亲切的感受,既让用户感受到机器人工作的严谨性与安全性,又让整个服务体验兼具友善、和谐与温度。

图12 · 机器人语音调性与语气规范
以“笃定”为例,表达语气的说明和示例,通过语气规范,统一整个语音交互原型的调性。

图13 · 语气规范示例
在设计时,我们可以用“真实的人物”来定义声音特征与沟通基调,分析、了解真实人物模型的个性特征。例如儿童早教类语音产品,可以以大家熟知的“金龟子”为人格原型进行定义,沟通中模仿她的语气、用词,让儿童感到亲切并符合服务对象的特征喜好。同时,我们需要设定“期望人们如何看待我们的语音产品”,传达怎样的服务理念。

图14 · 人物模型
但这里值得注意的是,现在很多语音助手支持语音选择,如男声、女声、少年等。我们要知道,“改变声音的同时,就意味着换了不同的人格”,他们的语音交互特征、形式等应该发生相应变化。同样一句很可爱、很活泼的话,小孩说合适,但如果换到“成熟男士”,多少会有些不合时宜。

图15 · 人物语气的多种性格
3.2 语音交互设计
语音设计的原型更像是“剧本设计”,需要考虑在哪个场景下,包含什么角色、他们如何对话、如何过度衔接、具体的语言如何等,如下图就是在此次项目中输出的语音设计原型,具体内容涉及到信息隐私,这里就不展开了,但是整个语音交互脚本中,对场景、角色、对话脚本备注图例、脚本正文等都做了明确定义与设计,后面就围绕如何做好交互引导、反馈、异常处理这四个方面进行介绍。

图16 · 语音交互脚本原型
3.2.1 语音交互引导
在设计语音脚本内容时,需要特别考虑VUI与人对话过程的语言衔接、对话内容的顺畅,并且能够自然的完成设想的任务。例如当询问用户信息时,最好给出一些示例,而不是说明。以下两句话大家可以明显感受到体验的差异,对于用户来说,参照示例填写信息,比理解一个通用指令更加容易。
“请告诉我你的出生日期,如2017年12月12日”
“请告诉我你的出生日期,包括年月日”
3.2.2 语音交互反馈
在GUI界面中,“确认反馈”随处可见,点击一个按钮、进行一个编辑操作,我们会设计不同重要程度的交互反馈;在VUI中,同样有不同程度的“确认反馈”,本文主要将他们分为三种:显性确认、隐形确认、视觉确认。

图17 · 语音交互反馈
3.2.3 语音交互异常处理
语音可能存在的异常情况主要有以下四种:
- 未检测到语音 (明确告诉用户“我没听清”)
- 检测到语音,但没有识别(“我不明白你的意思”)
- 语音被正确识别,但系统无法处理(“出现异常”)
- 部分语音识别错误(答非所问)
在设计中,我们可以按照不同的异常情况,设计多种播报脚本,提高产品容错性,缓解异常时候的尴尬,在此例举些常见的用户语音输入错误的回答,如图18。

图18 · 用户输入错误时的回答
04. 测试验证
4.1、语音设计原型测试
以项目中团队采用的两种脚本测试方式为例,分别是:剧本朗读和语音转换工具。通过剧本朗读,体验对话的流畅程度,确认是否存在对话呆板、重复、不自然的情况;通过文字转语音工具,如QQ语音转化,可以较真实的感受机器将对话说出来的效果。

图19 · 语音设计原型测试
4.2、语音及设备测试调优
设计交付后,功能开发完成,进入语音设备可运行阶段,这时系统具备测试功能。测试调优的方法同样给大家列举两个:一是可以通过开发、设计人员,进行实际人机测试,了解语音功能是否稳定、任务完成率如何、整个体验流程是否自然顺畅;二是可以通过用户观察的方法进行调研,找到符合特征的目标测试用户,利用机房的监控摄像头,观察“自然状态下”的用户如何工作,这样不会干扰用户,更贴近真实的使用情景。

图20 · 人机使用测试
05. 总结
以上是笔者首次接触语音交互设计的设计经过,对VUI设计中的知识点、流程、方法进行的总结,仍有很多不全面之处,后续随着项目的迭代和设计的深入,逐步去完善体验,总结沉淀。
【1】参考书籍:《语音用户界面设计》 Cathy Pearl (著)王一行(译)
作者:晏菲








评论0